코틀린에는 이름이 없는 람다식이라는 것이 있다.
이 람다식을 공부하면서 문득 이런 물음이 생겼다.
이름도 존재하고 형식도 익숙한 일반 함수가 이미 존재하는데, 왜 굳이 람다식을 사용하는걸까?
이 물음에 대한 나만의 답을 공유해보고자 한다!
함수형 프로그래밍 언어의 특징
일반 함수와 람다식의 차이를 알아보기 전에 꼭 짚어야할 점이 있다.
바로, 코틀린은 함수형 프로그래밍 언어라는 점이다.
(함수형 프로그래밍이 외부 환경과 독립적인 순수 함수를 지향하는 프로그래밍 방식이라는 점만 대략적으로 알고 넘어가자)
보통 함수형 프로그래밍 언어에서는 함수를 하나의 객체로 다루는 것이 가능하기 때문에
함수 자체를 다른 함수의 입출력으로 사용할 수가 있다.
이로 인해서 무엇이 달라지는 걸까?
우리가 자주 사용하는 find() 를 예로 살펴보자.
// list.find { condition }
val notZero: Int = myNumbers.find { it != 0 }
위와 같이 find 함수는 사용자가 원하는 조건식을 입력하면
조건에 해당하는 요소를 찾아내 반환해주는 유용한 함수이다.
이 때 사용자가 원하는 조건식은 블록문 { } 을 통해 전달되는데
이를 통해 조건식은 함수로 작성되어 전달된다는 것을 알 수 있다.
이 말은 즉,
우리는 find 함수를 사용할 때마다 조건식으로 사용할 새로운 함수 객체를 만들어 전달하며
함수를 다른 함수의 입력값으로 사용하고 있다는 것을 의미한다.
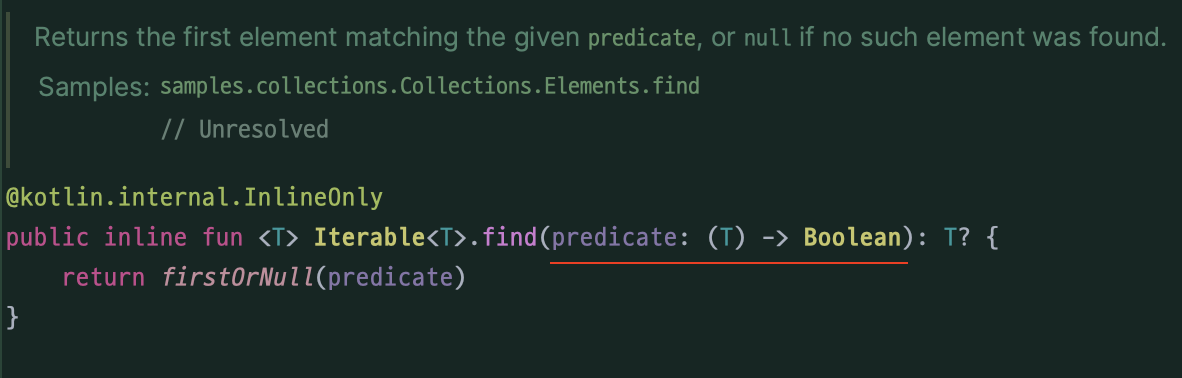
(find 함수의 매개변수를 보면 Int, String 같은 일반적인 자료형과 달리
(입력값) -> (결과값) 과 같은 함수 형태로 정의되어있는 것을 확인할 수 있다.)
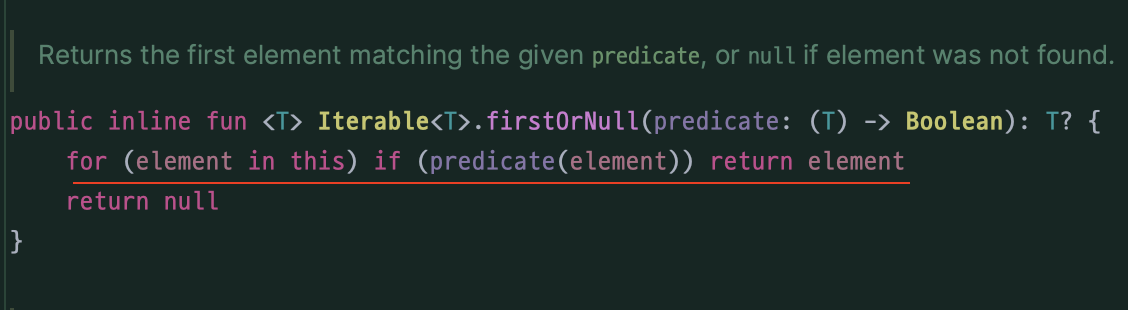
(그리고 find 함수가 반환하는 firstOrNull() 에서 내부적으로
사용자가 작성한 조건식 함수를 전달받아 요소를 골라내는데 사용하는걸 확인할 수 있다.)
만약 함수형 프로그래밍 방식이 아니였다면?
만약 코틀린이 함수형 프로그래밍 언어가 아니었다면 어떻게 find 함수를 사용해야했을까?
함수를 직접적으로 전달할 수 없으므로
조건 데이터를 다루는 클래스를 정의하고 객체를 생성하여 전달해야할 것이다.
interface Condition <T> {
fun predicate(data: T): Boolean
}
val myCondition = object : Condition<Int> {
override fun predicate(data: Int): Boolean {
return data != 0
}
}
val notZero: Int = myNumbers.find(myCondition)
위와 같이, 나만의 조건식을 담고 있는 객체를 생성해서 find 함수에 전달하고,
find 함수에서는 전달받은 myCondition 객체의 predicate() 에 접근해
정의돼있는 조건식을 만족하는 요소만 골라내어 반환하는 식으로 사용할 수 있을 것이다.
일반 함수와 람다식의 차이
앞서 함수를 하나의 객체로 다룰 수 있다는 함수형 프로그래밍 언어의 특징 덕분에
함수 외부에서 사용자가 정의하는 데이터를 편리하게 함수 내부로 전달할 수 있다는 점을 확인할 수 있었다.
그렇다면 왜 하필 람다식을 사용할까? 일반 함수에는 없는 람다식만의 특별한 이점이 존재하는 걸까?
결론부터 말하자면, 일반 함수만으로도 프로그래밍은 가능하다.
즉, 람다식을 사용하지 않아도 함수에 함수를 전달할 수 있다.
앞선 예시를 각각 일반 함수와 람다식을 사용하여 작성해보자
// 일반 함수를 사용한 경우
val notZeroByNormalFunc: Int = myNumbers.find(::predicate)
// 람다식을 사용한 경우
val notZeroByLabmda: Int = myNumbers.find{ it != 0 }
fun predicate(data: Int): Boolean {
return data != 0
}
(일반 함수를 사용했을 때 predicate 앞에 생소한 기호가 보이는데
:: 는 클래스나 함수를 참조할 때 사용된다)
일반 함수의 경우 이미 정의되어있는 함수를 참조하여 사용하는 반면에
람다식은 별도의 함수 정의 없이 곧바로 조건식을 작성하여 사용한다는 차이점이 있다.
내부적으로는 어떤 차이가 있을까?
- 컴파일 시점에서의 차이
먼저 일반 함수를 이용했을 때 Java 코드로 디컴파일한 결과를 확인해보자
val normalFunc = ::predicate
val myNumbers: List<Int> = listOf(1, 2, 3)
val notZeroByNormalFunc = myNumbers.find(normalFunc)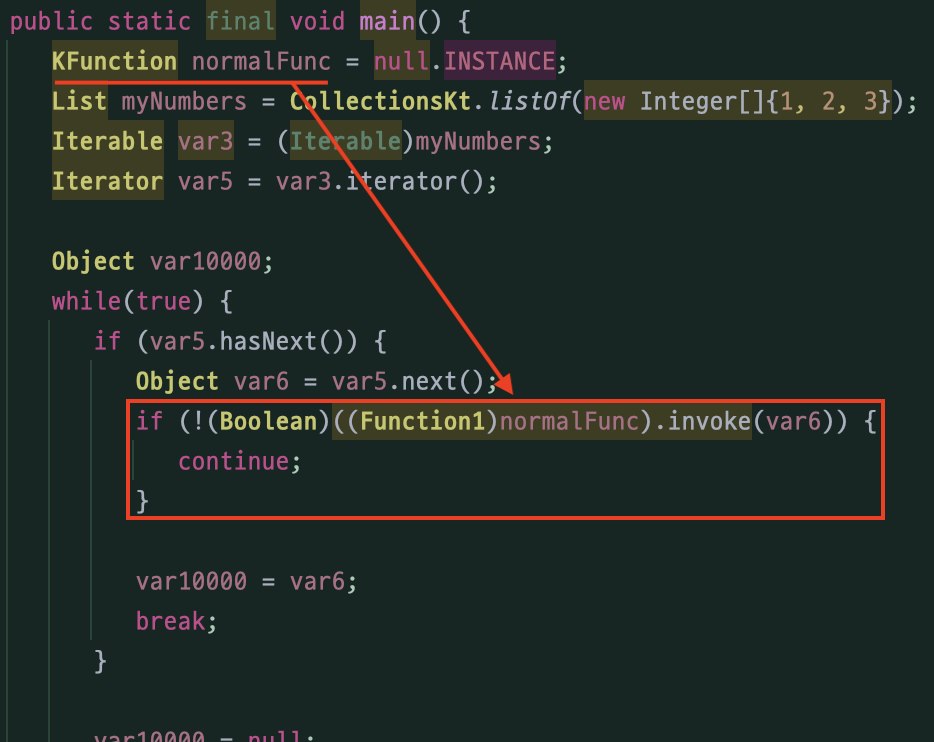
함수 참조 데이터를 가진 KFunction 타입의 normalFunc 가
실제 탐색 과정에서는 Function1 타입으로 변환되어 조건식으로 사용되는 것을 확인할 수 있다.
람다식의 결과도 확인해보자
val lambda = { data: Int -> data != 0 }
val myNumbers: List<Int> = listOf(1, 2, 3)
val notZeroByLambda = myNumbers.find(normalFunc)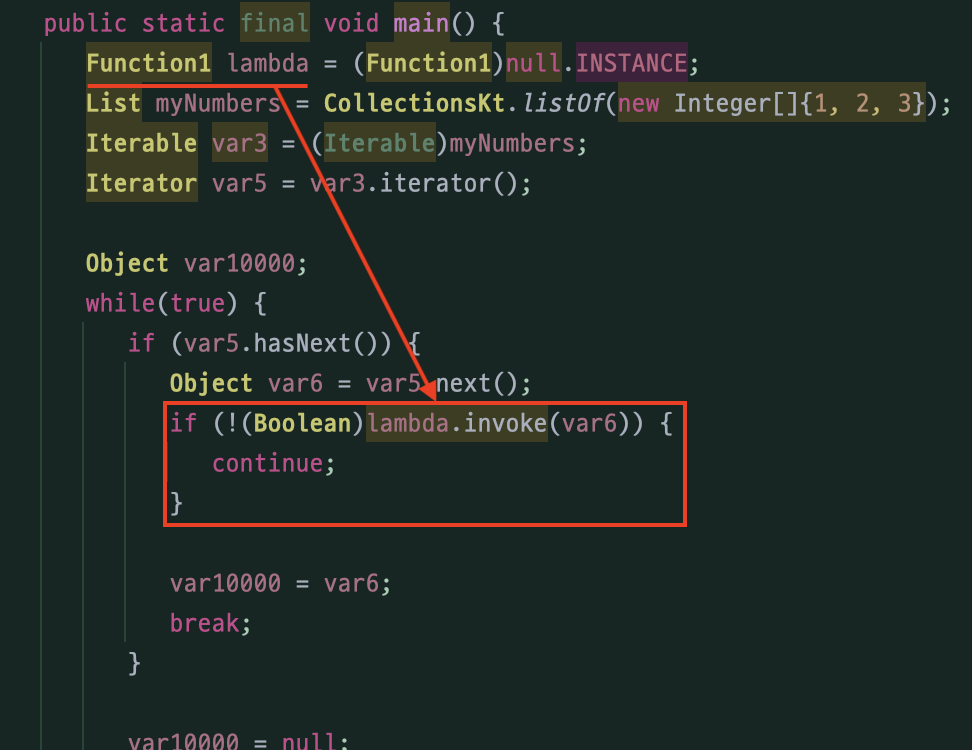
람다식의 경우 일반 함수와 달리
처음부터 Function1 타입으로 초기화된다는 점만 다르고
나머지 부분은 전부 동일한 것을 확인할 수 있다.



(KFunction 과 Function[N] 타입은 모두
함수를 일급 객체로 다루기 위해 코틀린 언어 차원에서 제공하는 클래스이다.)
결과적으로 컴파일 시점에서 일반 함수와 람다식을 사용하는 두 방법에 대한 확연한 차이는 없다는 것을 알 수 있었다.
- 런타임 시점에서의 차이
그렇다면 런타임에서는 어떤 차이가 있을까?
find 함수에 중단점을 걸고
각각 일반 함수와 람다식을 사용해 디버깅해보면 아래와 같은 스택 프레임 결과를 얻을 수 있다.
(일반 함수를 사용한 경우)
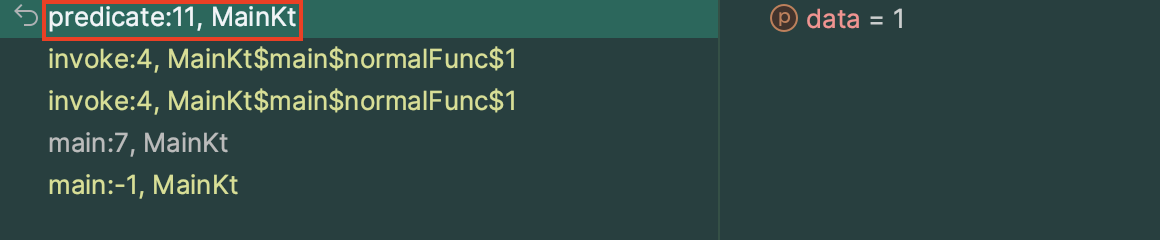
(람다식을 사용한 경우)
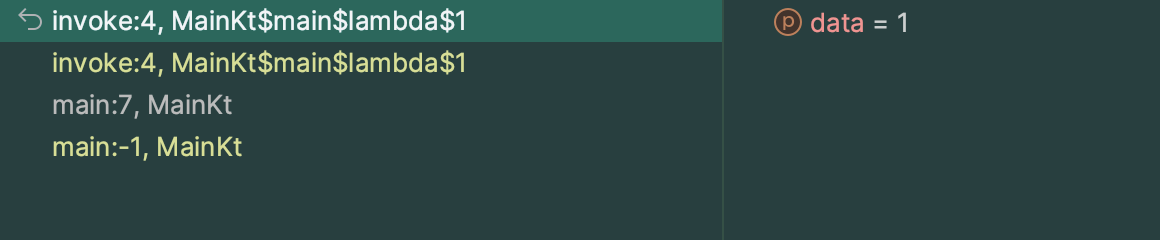
대부분의 과정이 전부 동일하지만, 일반 함수를 사용한 경우에만
참조 함수 원본에 찾아가 함수를 실행함으로써 스택에 프레임이 하나 추가된다는 차이점이 존재했다.
그렇다고 위 차이점이 두 함수간에 유의미한 차이가 있다고 할 수는 없다.
따라서 런타임 시점에서도 일반 함수와 람다식을 사용하는 두 방법 사이에 큰 차이는 없다는 것을 알 수 있다.
결론
함수형 프로그래밍 언어인 코틀린에서는 함수를 하나의 객체로 다루는 것이 가능하기때문에
별도 클래스를 생성하지 않고도 함수를 손쉽게 전달할 수 있다.
또한 함수를 객체로 다루고자 할 때 일반적으로 사용되는 함수와 람다식 모두 사용이 가능하지만
내부적으로 두 방법 사이에 큰 차이점이 존재하지는 않는다.
함수의 내용이 복잡해질 때도 과연 람다식이 항상 옳은 선택이라고 말할 수 있을까라는 의문이 들었지만
그럼에도 현재 람다식을 많이 사용하는데에는 성능이 아닌 가독성 측면에서 그만한 큰 이유가 있다고 생각한다.
따라서 다음에는 가독성 측면에서 람다식만이 주는 이점을 살펴보고자 한다.
'학습' 카테고리의 다른 글
| [Kotlin] 코틀린에서 tailrec 을 사용하는 이유 (0) | 2025.09.20 |
|---|